{kind=link}
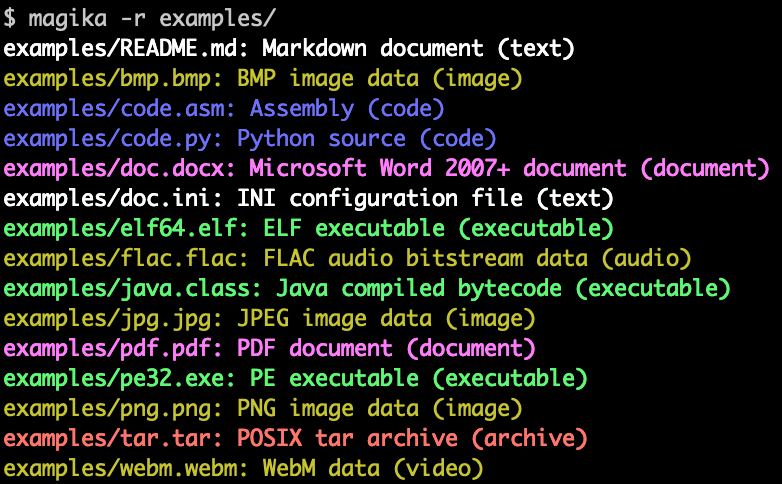
Компания Google объявила об открытии кода проекта Magika, предназначенного для определения типа содержимого на основе анализа имеющихся в файле данных. Magika может точно определять в содержимом используемые языки программирования, методы сжатия, установочные пакеты, исполняемый код, виды разметки, форматы звука, видео, документов и изображений. Связанный с проектом инструментарий и готовая модель машинного обучения опубликованы под лицензией Apache 2.0.
От похожих проектов, определяющих MIME-тип по содержимому, Magika отличается применением методов машинного обучения, высокой производительностью и отменной точностью определения. Модель обучена с использованием фреймворка Keras на 25 млн примерах файлов и поддерживает распознавание 116 типов данных с точностью не менее 99%. Модель скомпонована в формате ONNX и имеет размер всего 1 МБ. Задействование методов глубокого машинного обучения позволило на 50% повысить точность определения по сравнению с ранее применявшейся в Google системой на основе вручную заданных правилах.

В Google система используется для классификации файлов в сервисах Gmail, Drive, Code Insight и Safe Browsing при выполнения проверок безопасности и соответствия правилам сервисов. Ведётся работа по интеграции Magika в платформу VirusTotal в качестве звена для первичной фильтрации файлов перед выполнением специфичных анализаторов. Развёрнутая в инфраструктуре Google конфигурация Magika обеспечивает сканирование нескольких миллионов файлов в секунду и нескольких сотен миллиардов файлов в неделю. После загрузки модели время формирования вывода составляет 5-6 мс при тестировании на одном ядре CPU. Время определения почти не зависит от размера файла.
Для задействования Magika в своих проектах подготовлены утилита командной строки, пакет для Python и JavaScript-библиотека, способная работать в браузере или в проектах на базе Node.js. Интерфейс командной строки и API поддерживают выполнение операций в пакетном режиме, т.е. позволяют проверять несколько файлов за один запрос. Имеется режим рекурсивного сканирования всего содержимого каталога и три режима прогнозирования для настройки устойчивости к ошибкам (высокая уверенность, средняя уверенность и наилучшая догадка).