{kind=link}
Группа исследователей из трёх университетов Великобритании разработала усовершенствованный акустический метод атаки, позволяющий с 95% точностью определить информацию, вводимую на клавиатуре, анализируя звук от нажатия клавиш, записанный при помощи рядом лежащего смартфона или полученный с локального микрофона атакуемого устройства. Воссоздание ввода осуществляется с использованием классификатора на основе модели машинного обучения, учитывающей особенности звука и уровень громкости при нажатии разных клавиш.

Проведение атаки требует предварительного обучения модели, для которого необходимо сопоставить звук ввода с информацией о нажимаемых клавишах. В идеальных условиях для обучения модели может быть задействовано установленное на атакуемом компьютере вредоносного ПО, которое позволяет одновременно записывать звук с микрофона и перехватывать нажатия клавиш. В более реалистичном сценарии необходимые для обучения модели данные могут быть собраны через сопоставление вводимых текстовых сообщений со звуком набора, записанного в результате проведения видеоконференции. Точность определения ввода при обучении модели на основе анализа ввода в видеоконференциях Zoom и Skype уменьшается незначительно и составляет 93% и 91.7%, соответственно.
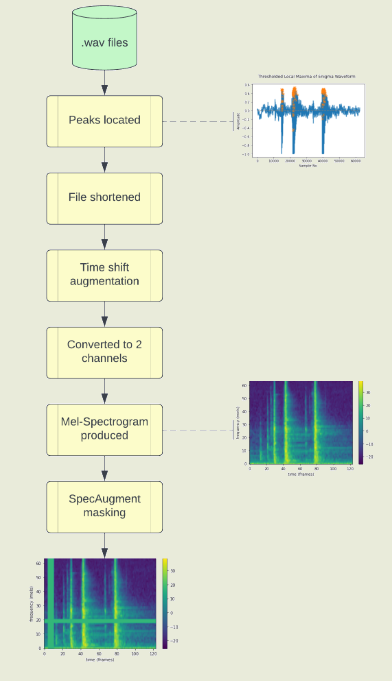
В ходе эксперимента для обучения модели машинного обучения, используя звук из Zoom-конференции, каждая из 36 клавиш (0-9, a-z) на клавиатуре нажималась 25 раз подряд разными пальцами и с разной силой. Данные о звуке каждого нажатия преобразовывались в картинку со спектрограммой, отражающей изменение частоты и амплитуды звука во времени. Спектрограммы передавались для обучения в классификатор на основе модели CoAtNet (Сonvolution and Attention Network), применяемой для классификации изображений в системах машинного зрения. Иными словами, при обучении картинка со спектрограммой каждого нажатия сопоставляются с названием клавиши. Для определения нажатых клавиш по звуку модель CoAtNet на основе переданной спектрограммы возвращает наиболее вероятную клавишу, по аналогии с возвращением наиболее вероятного тега при распознавании объектов по их изображению.
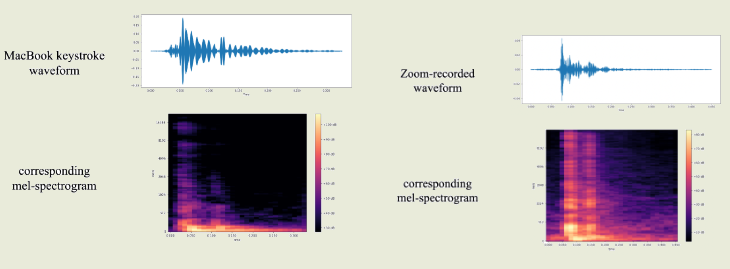
Продемонстрированная точность определения ввода превосходит все ранее известные методы посимвольного акустического анализа, не использующие языковую модель. Предложенный метод может применяться, например, для определения вводимых паролей или набираемых сообщений, в ситуации, когда атакующий разместил свой смартфон рядом с жертвой или получил запись звука во время набора конфиденциальной информации (например, когда во время общения жертва осуществляет вход с набором пароля в какою-то информационную систему). В дальнейшем исследователи намерены изучить возможность воссоздания клавиатурного ввода по записи звука с умных колонок, а также для повышения точности определения вводимого текста задействовать языковую модель, классифицирующую ввод в контексте целых слов.