Опубликован релиз проекта OpenZFS 2.1, развивающего реализацию файловой системы ZFS для Linux и FreeBSD. Проект получил известность как “ZFS on Linux” и ранее ограничивался разработкой модуля для ядра Linux, но после переноса поддержки FreeBSD был признан основной реализацией OpenZFS и был избавлен от упоминания Linux в названии.
Работа OpenZFS проверена с ядрами Linux c 3.10 по 5.13 и всеми ветками FreeBSD, начиная с 12.2-RELEASE. Код распространяется под свободной лицензией CDDL. OpenZFS уже используется во FreeBSD и входит в состав дистрибутивов Debian, Ubuntu, Gentoo, Sabayon Linux и ALT Linux. Пакеты с новой версией в ближайшее время будут подготовлены для основных дистрибутивов Linux, включая Debian, Ubuntu, Fedora, RHEL/CentOS.
OpenZFS предоставляет реализацию компонентов ZFS, связанных как с работой файловой системы, так и с функционированием менеджера томов. В частности, реализованы компоненты: SPA (Storage Pool Allocator), DMU (Data Management Unit), ZVOL (ZFS Emulated Volume) и ZPL (ZFS POSIX Layer). Дополнительно проектом обеспечена возможность использования ZFS в качестве бэкенда для кластерной файловой системы Lustre. Наработки проекта основаны на оригинальном коде ZFS, импортированном из проекта OpenSolaris и расширенном улучшениями и исправлениями от сообщества Illumos. Проект развивается при участии сотрудников Ливерморской национальной лаборатории по контракту с Министерством энергетики США.
Код распространяется под свободной лицензией CDDL, которая несовместима с GPLv2, что не позволяет добиться интеграции OpenZFS в состав основной ветки ядра Linux, так как смешивание кода под лицензиями GPLv2 и CDDL недопустимо. Для обхода данной лицензионной несовместимости было решено распространять продукт целиком под лицензией CDDL в виде отдельно загружаемого модуля, который поставляется отдельно от ядра. Стабильность кодовой базы OpenZFS оценивается как сопоставимая с другими ФС для Linux.
Основные изменения:
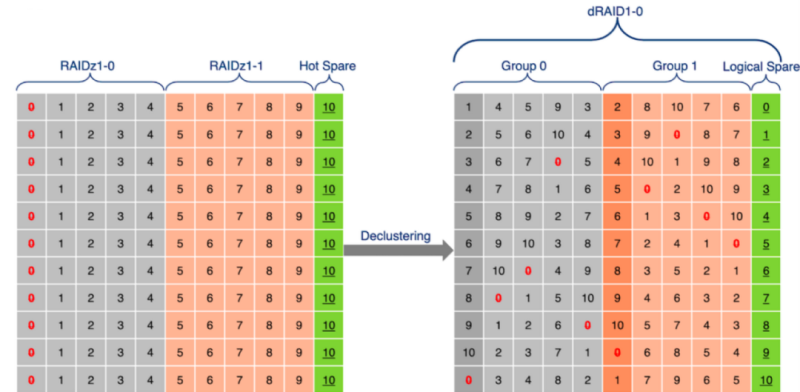
- Добавлена поддержка технологии dRAID (Distributed Spare RAID), которая представляет собой вариант RAIDZ с интегрированной распределённой обработкой блоков для горячего восстановления (hot spare). dRAID унаследовал все преимущества RAIDZ, но позволил добиться значительного увеличения скорости перестроения хранилища (resilvering) и восстановления избыточности в массиве. Виртуальное хранилище dRAID формируется из нескольких внутренних групп RAIDZ, в каждой из которой присутствуют устройства для хранения данных и устройства для хранения блоков чётности. Указанные группы распределены по всем накопителям для оптимального использования доступной пропускной способности дисков. Вместо отдельного диска для горячего восстановления в dRAID применяется концепция логического распределения блоков для горячего восстановления по всем дискам в массиве.

- Реализовано свойство “compatibility” (“zpool create -o compatibility=off|legacy|file[,file…] pool vdev”), позволяющее администратору выбрать набор возможностей, которые следует активировать в пуле, с целью создания переносимых пулов и поддержания совместимости пулов между разными версиями OpenZFS и разными платформами.
- Предоставлена возможность сохранения статистики о работе пула в формате СУБД InfluxDB, оптимизированной для хранения, анализа и манипулирования данными в форме временного ряда (срезы значений параметров через заданные промежутки времени). Для экспорта в формат InfluxDB предложена команда “zpool influxdb”.
- Добавлена поддержка горячего добавления памяти и CPU.
- Новые команды и опции:
- “zpool create -u” – запрет автоматического монтирования.
- “zpool history -i” – отражение в истории операций длительности выполнения каждой команды.
- “zpool status” – добавлен вывод предупреждения о дисках с неоптимальным размером блока.
- “zfs send –skip-missing|-s” – игнорирование отсутствующих снапшотов в процессе отправки потока для репликации.
- “zfs rename -u” – переименование ФС без перемонтирования.
- В arcstat добавлена поддержка статистики L2ARC и добавлены опции “-a” (all) и “-p” (parsable).
- Оптимизации:
- Повышена производительность интерактивного ввода/вывода.
- Ускорена работа prefetch для нагрузок, связанных с параллельным доступом к данным.
- Улучшена масштабируемость за счёт снижения конфликта блокировок.
- Сокращено время импорта пула.
- Сокращена фрагментация ZIL-блоков.
- Повышена производительность рекурсивных операций.
- Улучшено управление памятью.
- Ускорена загрузка модуля ядра.
{kind=link}