Компания Яндекс опубликовала исходные тексты распределённой СУБД YDB, реализующей поддержку диалекта SQL и ACID-транзакций. СУБД создана с нуля и изначально развивается с оглядкой на обеспечение отказоустойчивости, автоматического восстановления при сбоях и масштабируемости. Отмечается, что компанией Яндекс запущены рабочие кластеры YDB, включающие более 10 тысяч узлов, хранящие сотни петабайт данных и обслуживающие миллионы распределённых транзакций в секунду. YDB используется в таких проектах Яндекс, как Маркет, Облако, Умный Дом, Алиса, Метрика и Auto.ru. Код написан на языках C/C++ и распространяется под лицензией Apache 2.0.
Особенности проекта:
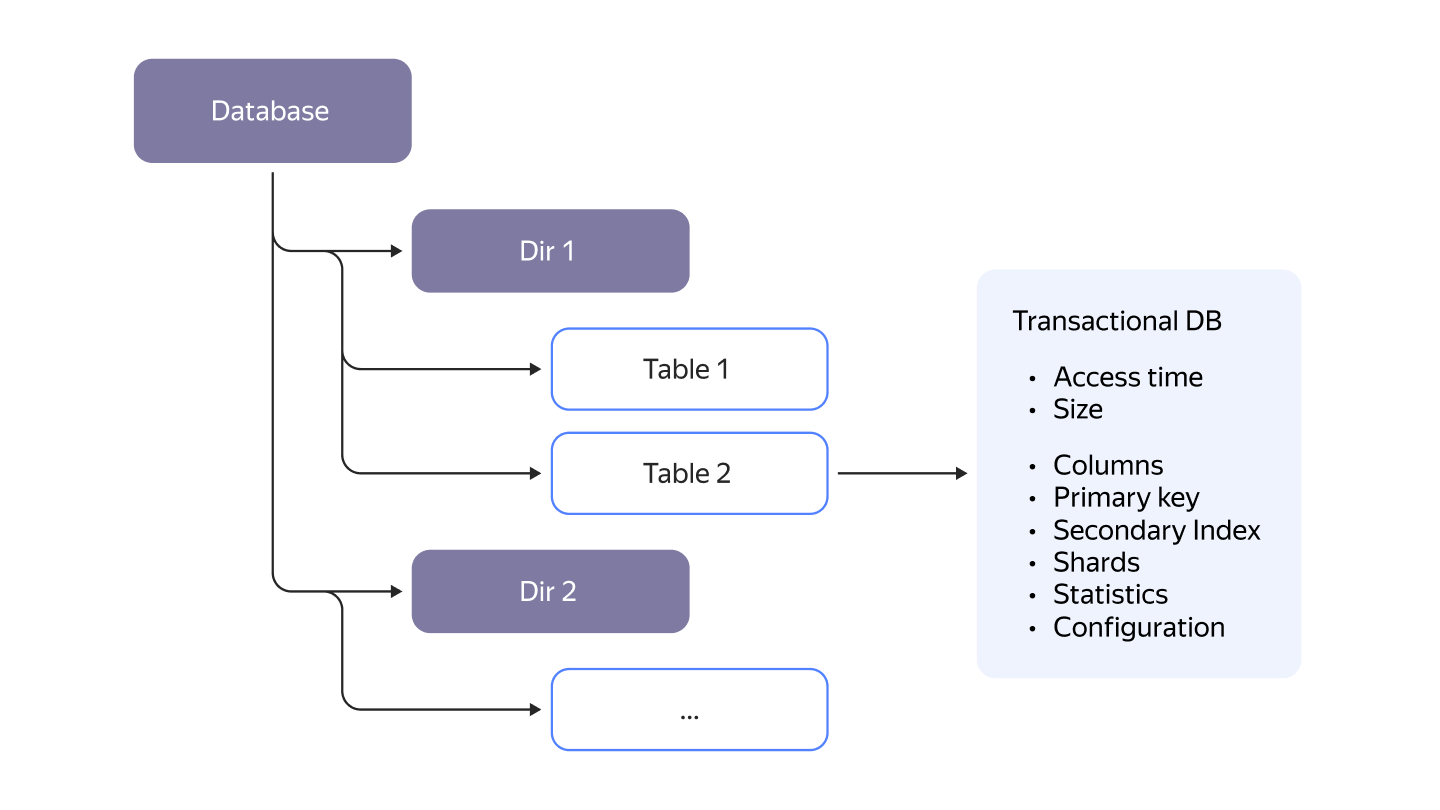
- Использование реляционной модели данных с таблицами. Для запросов и определения схемы данных используется язык YQL (YDB Query Language), представляющий собой диалект SQL, адаптированный для работы с большими распределёнными базами данных. При создании схемы хранения поддерживается древовидная группировка таблиц, напоминающая каталоги в файловой системе. Предоставляется API для работы с данными в формате JSON.

- Поддержка доступа к данным с использованием скан запросов, предназначенных для выполнения аналитических ad-hoc запросов над БД, выполняемых в режиме только для чтения и возвращающих поток grpc.
- Взаимодействие с СУБД и отправка запросов осуществляется при помощи интерфейса командной строки или набора YDB SDK, предоставляющего библиотеки для языков C++, С# (.NET), Go, Java, Node.js, PHP и Python.
- Возможность создания отказоустойчивых конфигураций, продолжающих работу при выходе из строя отдельных дисков, узлов, стоек и даже датацентров. YDB поддерживает развёртывание и синхронную репликацию в трёх зонах доступности с сохранением работоспособности кластера в случае выхода из строя одной из зон.
- Автоматическое восстановление после сбоев с минимальными задержками для приложений и автоматическое поддержание заданной избыточности при хранении данных.
- Автоматическое создание индексов по первичному ключу и возможность определение вторичных индексов для повышения эффективность доступа к произвольным колонкам.
- Горизонтальная масштабируемость. По мере роста нагрузки и размера хранимых данных кластер можно расширять простым подключением новых узлов. Уровни для вычислений и хранения разделены, что позволяет раздельно наращивать вычислительную мощность и размер хранилища.
СУБД сама следит за равномерным распределением данных и нагрузки с учётом имеющихся аппаратных ресурсов. Возможно развёртывание территориально распределённых конфигураций, охватывающих несколько датацентров в разных частях света. - Поддержка модели строгой непротиворечивости и ACID-транзакций при обработке запросов, охватывающих несколько узлов и таблиц. Для повышения производительности возможно выборочное отключение контроля непротиворечивости.
- Автоматическая репликация данных, автоматическое секционирование (партицирование, шардирование) при увеличении размера или нагрузки и автоматическая балансировка нагрузки и данных между узлами.
- Хранение данных непосредственно на блочных устройствах, используя собственный компонент PDisk и прослойку VDisk. Поверх VDisk выполняется DSProxy, который анализирует доступность и характеристики работы дисков, для их исключения в случае выявления проблем.
- Гибкая архитектура, позволяющая создавать поверх YDB, различные сервиcы, вплоть до виртуальных блочных устройств. Пригодность применения для разных видов нагрузки, OLTP и OLAP (аналитические запросы).
- Поддержка многопользовательских (multitenant) и бессерверных конфигураций. Возможность аутентификации клиентов. Пользователи могут создавать свои виртуальные кластеры и БД в общей совместной инфраструктуре с учётом потребления ресурсов на уровне числа запросов и размера данных или арендуя/резервируя определённые вычислительные ресурсы и объём в хранилище.
- Возможность настройки времени жизни записей для автоматического удаления устаревших данных.
{kind=link}
Release.
Ссылка here.