{kind=link}
Twitter открыл исходные тексты набора “Recommendation Algorithm“, включающего сервисы и обработчики, применяемые при построении ленты рекомендованных сообщений, показываемой пользователю на основной странице (Home Timeline). Кроме обеспечения прозрачности и предоставления возможности независимого аудита применяемых алгоритмов, Twitter выразил готовность принимать от сообщества pull-запросы с улучшающими работу алгоритмов изменениями, которые после рецензирования могут быть перенесены в рабочую кодовую базу Twitter.
Код открыт под лицензией AGPLv3. В реализации использованы языки программирования Scala (53.8%), Java (29.7%), Starlark (6.3%), Python (4.7%), C++ (2.4%) и Rust (1.5%). В отдельном репозитории опубликован код, связанный с применяемыми в Twitter моделями машинного обучения (сами модели не опубликованы из соображений безопасности и сохранения конфиденциальности). Не опубликованными также остаются компоненты для формирования рекламных рекомендаций.
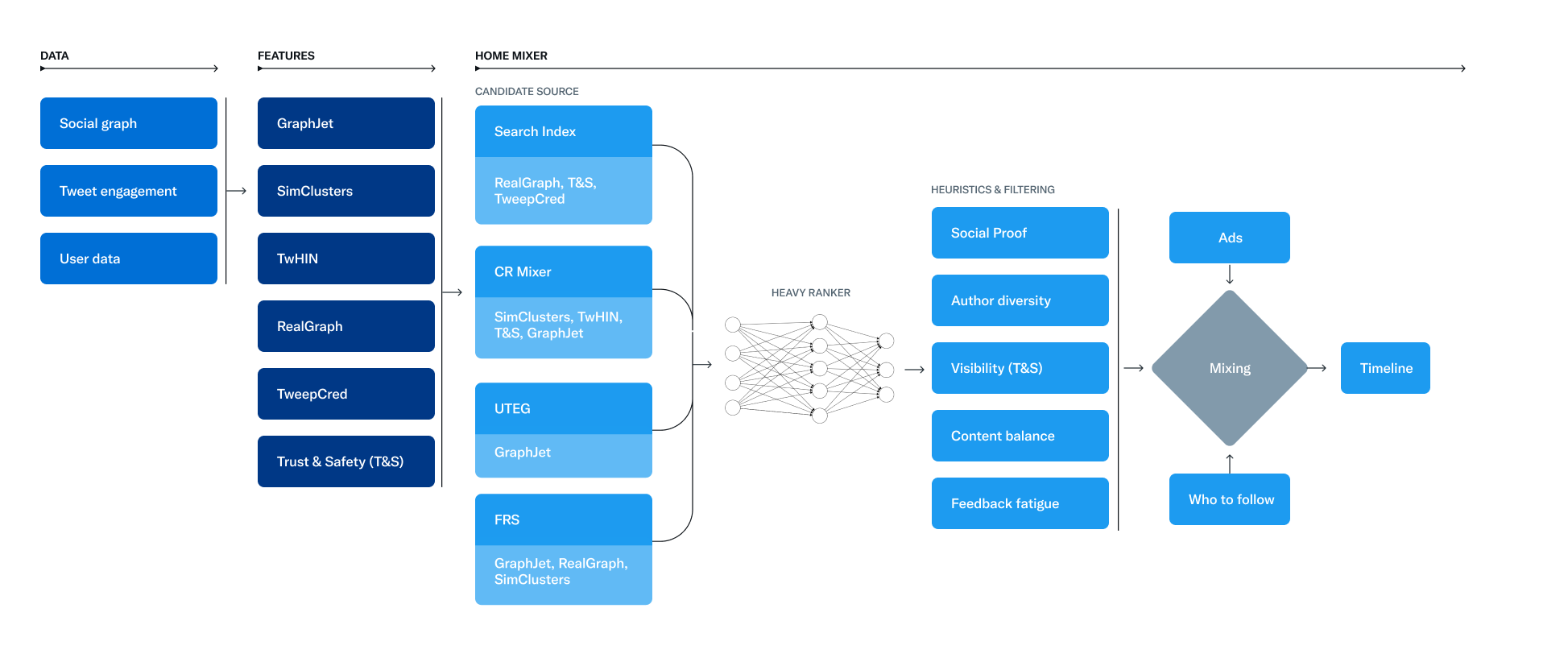
Построение ленты рекомендаций разделено на три основные стадии:
- Извлечение лучших твитов из разных источников (candidate sourcing). На данной стадии в качестве источников используются:
система индексации search-index, которая охватывает сообщения людей, на которые имеется подписка (In-Network); прослойка cr-mixer для извлечения сообщений из различных вспомогательных сервисов, охватывающих сообщений от людей, на которых не оформлена подписка (Out-of-Network); компонент user-tweet-entity-graph (UTEG) для извлечения сообщений с учётом графа взаимодействия текущего пользователя; сервис follow-recommendation-service (FRS) для формирования рекомендаций на основе активности отслеживаемых пользователей (на которых оформлена подписка). При выборке 50% сообщений показывается от людей, на которых имеется подписка. - Ранжирование отобранных твитов с использованием модели машинного обучения. Применяется две системы ранжирования: модель light-ranker , использующая поисковый индекс, и нейронная сеть heavy-ranker для выбора наиболее релевантных кандидатов.
- Применение фильтров и эвристики для отсеивания заблокированных, непристойных или уже просмотренных сообщений. Для формирования ленты используется компонент home-mixer, а для фильтрации система visibility-filters (дополнительно открыт код старой системы timelineranker, применявшейся для извлечения твитов из поискового индекса).
Также открыт код вспомогательных компонентов:
- simclusters-ann – определение сообществ со сходными интересами.
- TwHIN – формирование графов знаний о пользователях и твитах (подписчики, выбранные пользователем твиты, клики на рекламу).
- trust-and-safety-models – модели для выявления нежелательного, нецензурного и оскорбительного контента.
- real-graph – модель для предсказания взаимодействия между разными пользователями.
- tweepcred – алгоритм для вычисления репутации пользователя с учётом ссылок на его сообщения (Page-Rank).
- recos-injector – обработчик потока событий, формирующий входные данные для сервисов GraphJet.
- graph-feature-service – предоставляет графовые функции для оценки взаимодействия двух пользователей, например, сколько пользователь “A” оценил твитов пользователя “B”.
- navi – высокопроизводительный инструментарий для обработки моделей машинного обучения (написан на Rust).
- product-mixer – построитель лент с контентом из разных источников.
- twml – старый фреймворк машинного обучения (ответвление от TensorFlow v1).