{kind=link}
Исследователи из компании JFrog выявили в репозитории Hugging Face вредоносные модели машинного обучения, установка которых может привести к выполнению кода атакующего для получения контроля за системой пользователя. Проблема вызвана тем, что некоторые форматы распространения моделей допускают встраивание исполняемого кода, например, модели, использующие формат “pickle”, могут включать сериализированные объекты на языке Python, а также код, выполняемый при загрузке файла, а модели Tensorflow Keras могут исполнять код через Lambda Layer.
Для предотвращения распространения подобных вредоносных моделей в Hugging Face применяется сканирование на предмет подстановки сериализированного кода, но выявленные вредоносные модели показывают, что имеющиеся проверки можно обойти. Всего выявлено около 100 потенциально вредоносных моделей, 95% из которых предназначены для использования с фреймворком PyTorch, а 5% c Tensorflow. Наиболее часто встречающимися вредоносными изменениями названы захват объекта, организация внешнего входа в систему (reverse shell), запуск приложений и запись в файл.
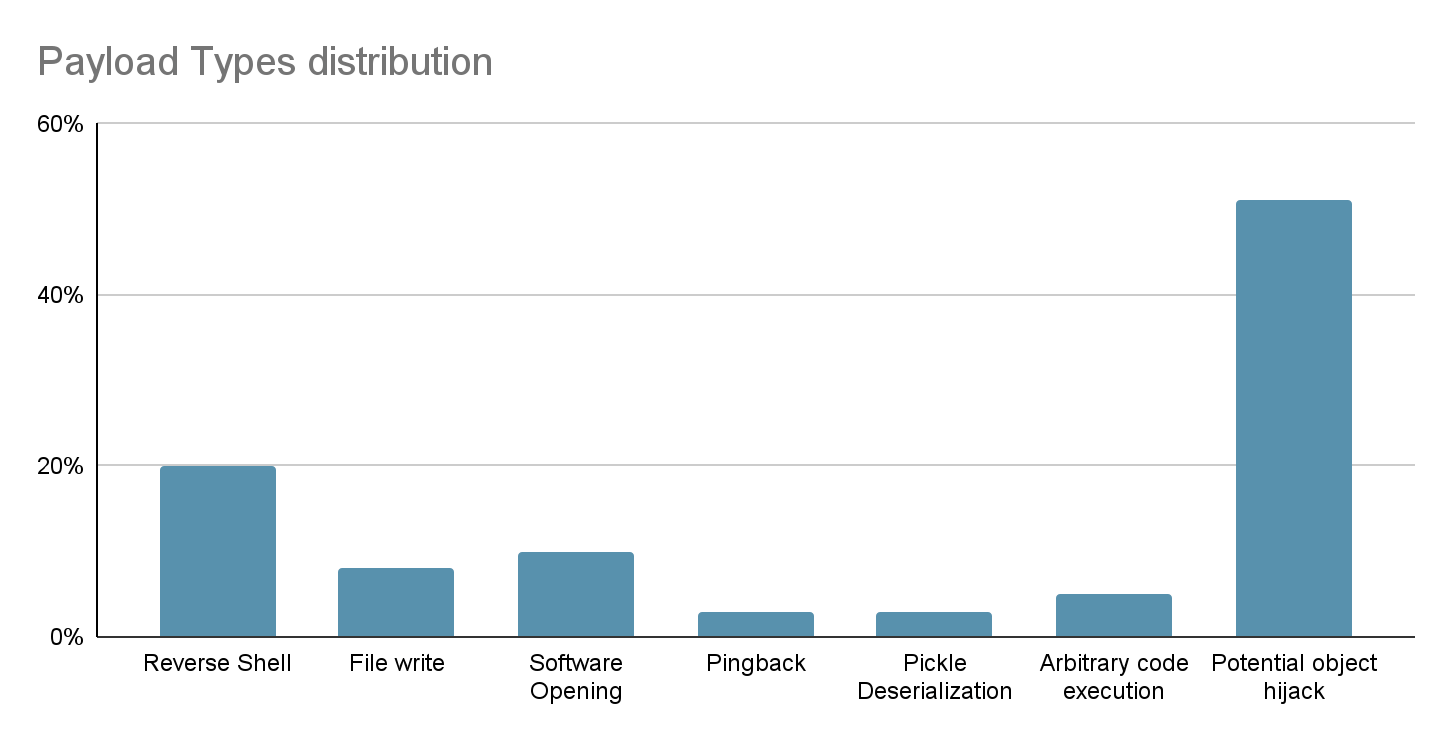
Отмечается, что судя по совершаемым действиям большинство выявленных вредоносных моделей созданы исследователями безопасности, пытающимися получить вознаграждение за обнаружение уязвимостей и методов обхода защиты Hugging Face (например, вместо реальной атаки подобные модели пытаются запустить калькулятор или отправить сетевой запрос с информацией об успехе атаки). При этом встречаются и экземпляры, запускающие обратный shell для подключения атакующего к системе.
Например, модели “baller423/goober2 и “star23/baller13” нацелены на совершения атаки на системы, загружающие файл модели в PyTorch при помощи функции torch.load(). Для организации выполнения кода задействован метод “__reduce__” из модуля pickle, позволяющий вставить произвольный Python-код в процесс десериализации, выполняемый при загрузке модели.