{kind=link}
Организации Apache Software Foundation представила выпук распределённого OLAP-хранилища Apache Pinot 1.0, предназначенного для выполнения аналитических запросов. Изначально проект Pinot был разработан компанией LinkedIn и в 2015 году передан для дальней совместной разработки фонду Apache. Хранилище ориентировано на работу в условиях постоянного добавления новых данных и рассчитано на обеспечение минимальных и предсказуемых задержек, позволяющих использовать хранилище для обработки запросов в реальном времени. Код проекта написан на Java и распространяется под лицензией Apache.
В Apache Pinot обеспечивается горизонтальная масштабируемость и предоставляются средства достижения отказоустойчивости и сохранения живучести при возникновении программных и аппаратных ошибок. Процессы репликации и резервного копирования встроены непосредственно в цикл обработки добавляемых в хранилище данных. С одной стороны такой подход позволяет значительно упростить архитектуру, но, с другой стороны, приводит к возникновению задержки между добавлением данных и их доступностью для запросов. Данные в хранилище могут загружаться из разных источников, начиная Hadoop и обычных файлов и заканчивая получением информации от online-источников, таких как Kafka. Для управления Pinot-кластером применяется Apache Helix.
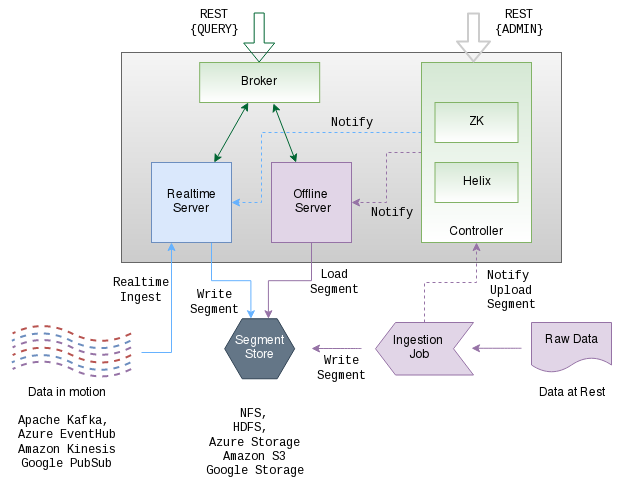
Обращение к хранилищу производится через привычный язык запросов SQL, поддерживающий типовые операции фильтрации выборки, агрегирования, сортировки, слияния (JOIN) и группировки данных. Имеется поддержка оконных функций. Данные размещаются в таблицах базы данных, ориентированной на столбцы (column-oriented). Поддерживаются различные схемы сжатия и возможность размещения нескольких значений в одном поле. Pinot предоставляет подключаемую систему индексов, в которой можно применять различные технологии индексации (отсортированный индекс, Bitmap-индекс, инвертированный индекс, StarTree-индекс, Bloom Filter, индекс по диапазонам, индекс для поиска текста (Lucence/FST), JSON-индекс, геопространственный индекс).
Выпуск 1.0 подвёл итог большой работы по стабилизации кодовой базы и учёту пожеланий сообщества (учтено более 300 замечаний). До полноценного состояния доведён новый движок многоэтапной обработки запросов (Multi-Stage Query Engine), позволивший реализовать поддержку слияния таблиц (JOIN). Изначально используемый движок прекрасно справлялся с простыми операциями фильтрации и агрегирования, но для обеспечения предсказуемого времени выполнения запроса не поддерживал операции слияния таблиц. В новом движке задействованы промежуточные стадии обработки сложных запросов, а семантика SQL приближена к ANSI SQL. Кроме того, в новом выпуске предложена встроенная поддержка обработки данных в формате JSON, реализована поддержка значения “NULL”, реализована интеграция с Apache Spark 3.x и улучшена реализация таблиц в режиме Upsert (добавлено сжатие сегментов и предоставлена поддержка операций удаления).