Компания Яндекс объявила об открытии исходного кода инструментария Perforator, предназначенного для непрерывного сбора детальных метрик с информацией о работе приложений и рассчитанного на использование в крупных кластерах и датацентрах. Инструментарий позволяет анализировать работу приложений в реальном времени, оценивать распределение ресурсов на Linux-серверах и выявлять наиболее ресурсоёмкие приложения. Код написан на языке С++ и распространяется под лицензией MIT (eBPF-программы под GPLv2).
В Яндекс Perforator развёрнут в кластере, насчитывающем более 10 тысяч узлов, и применяется для выявления и исправления проблем с производительностью в различных сервисах. Отмечается, что благодаря устранению узких мест и оптимизации вычислений компании Яндекс удалось на 20% снизить расходы на серверы.
Заявленные возможности:
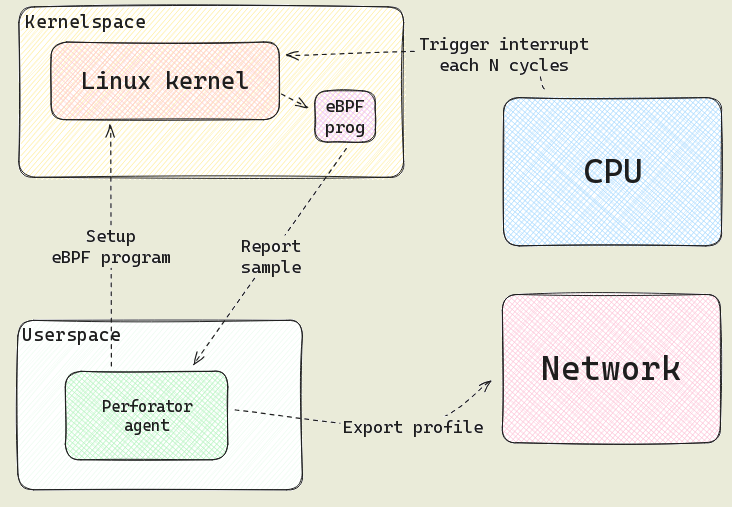
- Использование подсистемы ядра eBPF для сборка сведений о работе компонентов ядра и пространства пользователя. Накладные расходы при сборе метрик оцениваются примерно в снижение производительности на 0.1%.
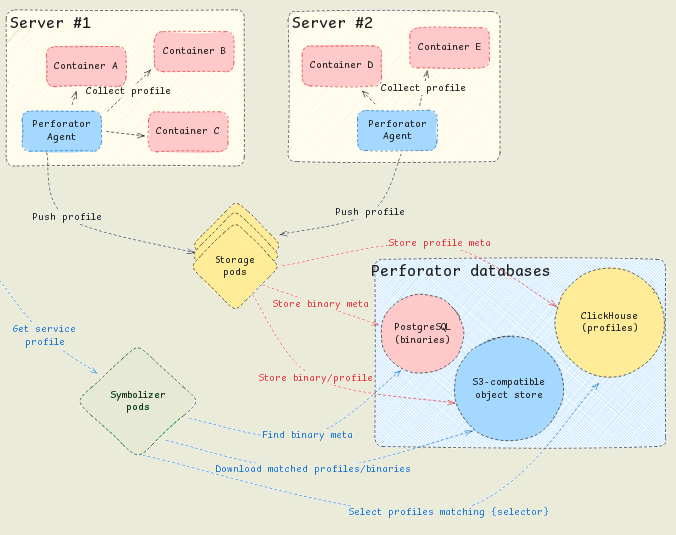
- Масштабируемое хранилище для хранения профилей производительности. Для хранения метаданных профилей используется СУБД
ClickHouse, для хранения бинарных метаданных – PostgreSQL, а для хранения raw-профилей и бинарных данных – любые хранилища, совместимые с Amazon S3. - Возможность раскрутки стека вызовов (unwinding) в системных окружениях без необходимости включения при сборке отладочных символов и опции “-fno-omit-frame-pointer” (сохраняет указатель на кадр стека, содержащий адреса возврата и переменные функции).
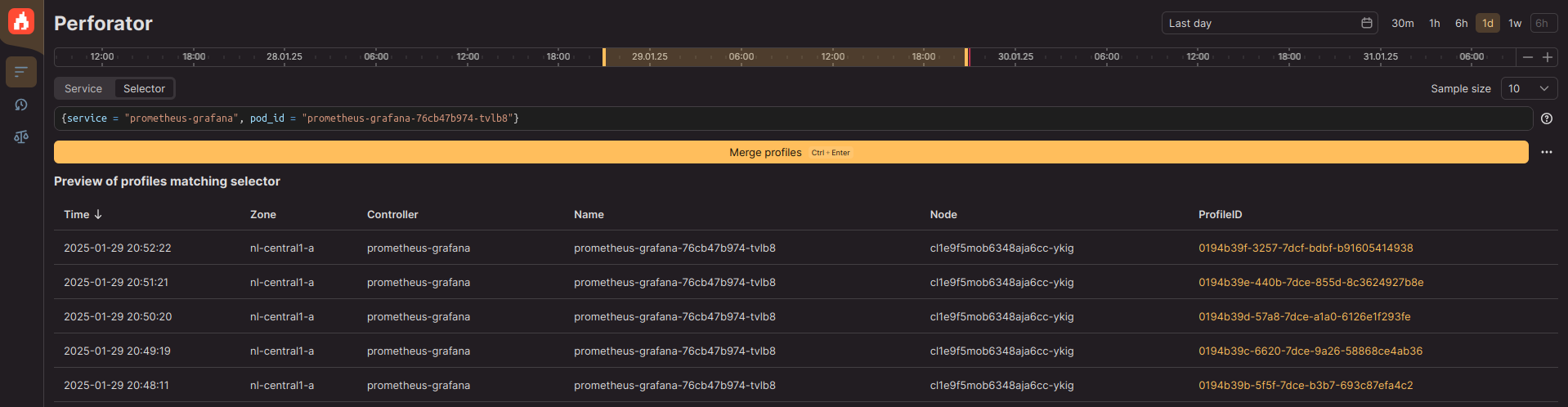
- Наличие языка запросов и web-интерфейса для инспектирования нагрузки на CPU при работе приложений.

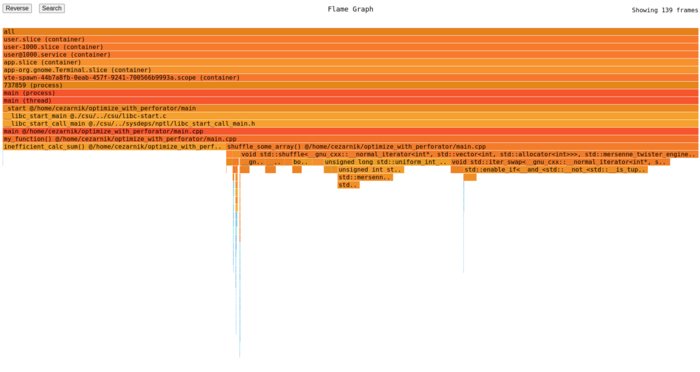
- Для наглядной оценки узких мест применяется визуализация в стиле FlameGraph.
- Возможность профилирования проектов, использующих различные языки и runtime, без внесения изменений в сборочные процессы и без перекомпиляции программ. Поддержка языков программирования C++, Go, Rust, Java, Python, JavaScript/Node.js.
- Возможность генерации профилей sPGO для сборки приложений с оптимизации на основе результатов профилирования кода (PGO – Profile-guided optimization), позволяющей генерировать более оптимальный код на основе анализа особенностей выполнения программы.
- Поддержка использования в качестве замены инструментария perf в Linux.
- Автоматизация развёртывания в кластерах на базе Kubernetes. На каждом узле запускается специальный агент, собирающий (используется обработчик на базе eBPF и API perf_events), агрегирующий, сжимающий и передающий данные о производительности. Данные передаются агентами через gRPC в микросервисы, отвечающие за сбор, хранение, анализ, символизацию (преобразование адресов в имена функций и позиции в коде) и обработку профилей и исполняемых файлов (необходимы при раскрутке стека).
{kind=link}