{kind=link}
Компания Яндекс объявила об открытии исходных текстов платформы распределённого хранения и обработки больших объёмов данных YTsaurus, поддерживающей манипуляцию данными с использованием парадигмы MapReduce, движка SQL-запросов, распределённой файловой системы и NoSQL хранилища в формате ключ-значение. YTsaurus используется в инфраструктуре Яндекс для эффективного использования вычислительных мощностей суперкомпьютеров компании. Код проекта написан на языках C/C++ и открыт под лицензией Apache 2.0.
Платформа может масштабироваться до кластеров, включающих более 10 тысяч узлов и охватывающих до миллиона процессоров и тысяч GPU (для решения задач машинного обучения). В качестве образующих кластер единиц могут использоваться изолированные контейнеры, запускаемые на физических серверах. В хранилище могут находится эксабайты данных, размещённых на различных носителях, таких как жёсткие диски, SSD, NVME и оперативная память. В кластере поддерживается динамическое добавление и удаление узлов, резервирование (нет единой точки отказа), автоматическая репликация, обновление кластерного ПО без остановки работы и автоматическое восстановление избыточности в случае выхода узлов из строя.
Поддерживается три вида кластеров: вычислительные кластеры (для массивной параллельной обработки больших данных при помощи операций MapReduce), кластеры для динамических таблиц и хранилища в формате ключ-значение и геораспределённые кластеры. Сервис на базе платформы может предоставлять средства для хранения и обработки данных десятков тысяч пользователей. Среди типовых областей применения YTsaurus в Яндекс называется хранение информации о пользователях рекламной сети,
обучение моделей машинного обучения, формирование поискового индекса и
построение хранилища данных для таких сервисов, как Яндекс Такси, Еда, Лавка и Доставки.
Базовые сценарии использования:
- Batch-обработка. MapReduce и SPYT (Apache Spark в качестве вычислительного движка поверх данных в YTsaurus) для обработки структурированных и полуструктурированных данных: логов или финансовых транзакций.
- Ad hoc аналитика. Быстрые запросы через CHYT (кластер из серверов ClickHouse на вычислительных узлах YTsaurus) без копирования данных в отдельную аналитическую систему. ODBC и JDBC с возможностью подключить BI для визуализации.
- OLTP-задачи. Транзакционная работа в реальном времени с хранилищем в формате ключ-значение: например, для хранения профилей пользователей, показа рекламы или потоковой обработки.
- Машинное обучение. Управление кластерами GPU для обучения моделей с миллиардами параметров.
- Хранилище метаинформации. Транзакционное хранение метаинформации и надёжный сервис распределённых блокировок.
- Построение хранилищ данных и ETL для многоуровневой обработки данных при помощи типовых инструментов: Apache Spark, SQL, MapReduce.
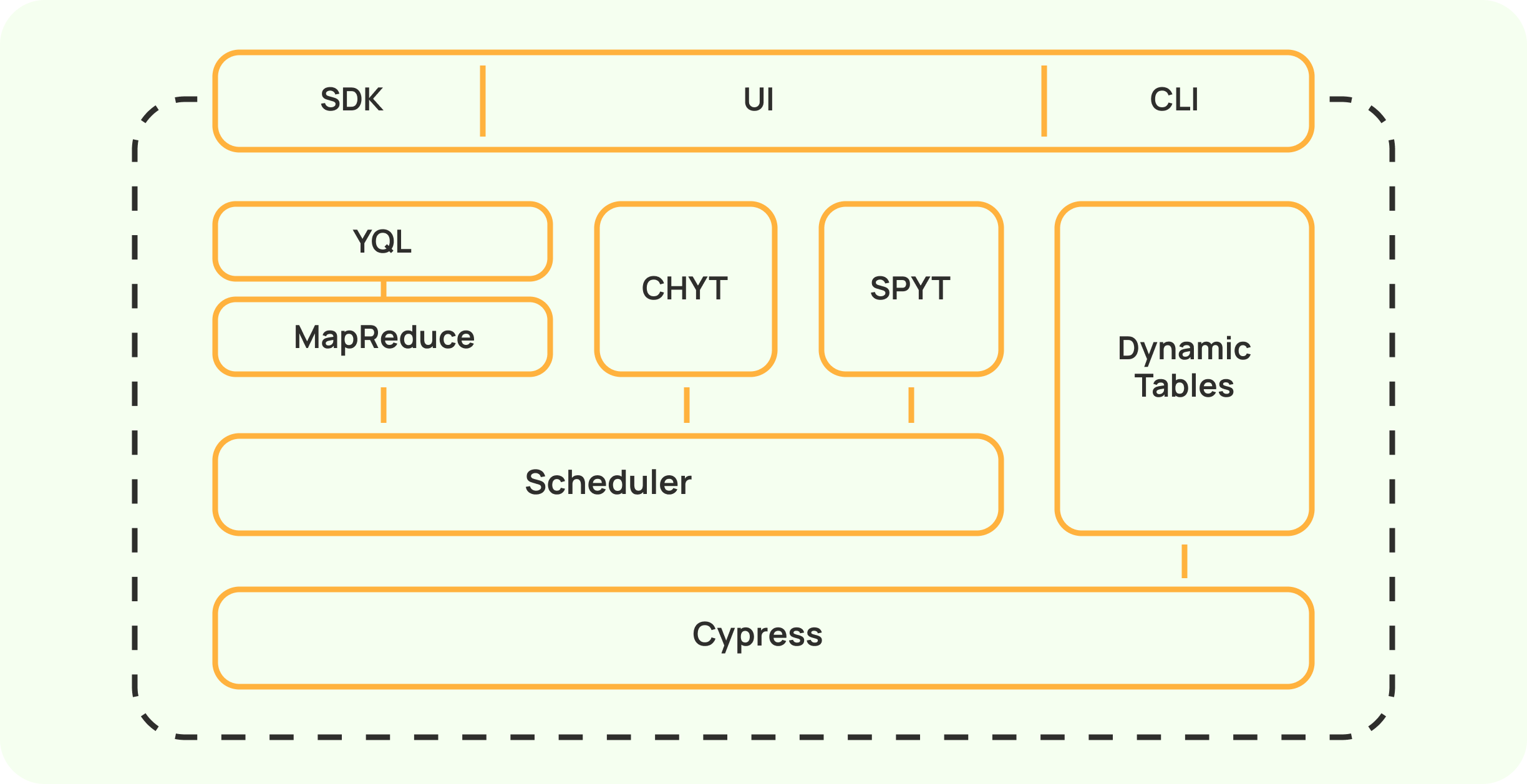
Основные элементы архитектуры:
- Распределённая файловая система и отказоустойчивое древовидное хранилище метаинформации Cypress. Поддерживается хранение в форме файлов и таблиц (с разбивкой на колонки и строки), прозрачное секционирование таблиц, сжатие данных (lz4 и zstd), поддержание кодов для восстановления в случае потери информации и контрольных сумм, фоновая репликация, транзакции, разграничение прав доступа (вплоть до уровня колонок таблиц).
- Планировщик для распределённых вычислений с поддержкой модели MapReduce, а также расширенных базовых операций, таких как Erase и Sort. Горизонтальная масштабируемость вычислительных операций.
Изоляция вычислительных ресурсов и возможность выделять определённые вычислительные ресурсы (CPU, GPU, ОЗУ) в разных пропорциях. - Высокоуровневые вычислительные движки для аналитических запросов CHYT (ClickHouse поверх YTsaurus), SPYT (Apache Spark поверх YTsaurus). Движок YQL с реализацией диалекта SQL, поддерживающего операции слияния (join), подзапросы, оконные функции и параллельное исполнение запросов произвольной сложности.
- Динамические таблицы для создания OLTP-хранилища, поддерживающие хранение на базе модели MVCC, транзакции и собственный диалект SQL – YQL, возможность удаления данных после истечения времени жизни. Очереди сообщений для организации потоковой обработки данных поверх динамических таблиц.
- API и библиотеки для языков программирования С++, Python, Java, Go.
- Web-интерфейс для пользователей и администраторов, поддерживающий навигацию по древовидному хранилищу, выполнение операций с таблицами, каталогами и файлами, отправку SQL-запросов, мониторинг за кластером, управление пользователями, назначение квот, разграничение доступа и т.п.